The Power of Modern Linux System Management
In today’s world of high-performance computing, efficient resource management is critical.
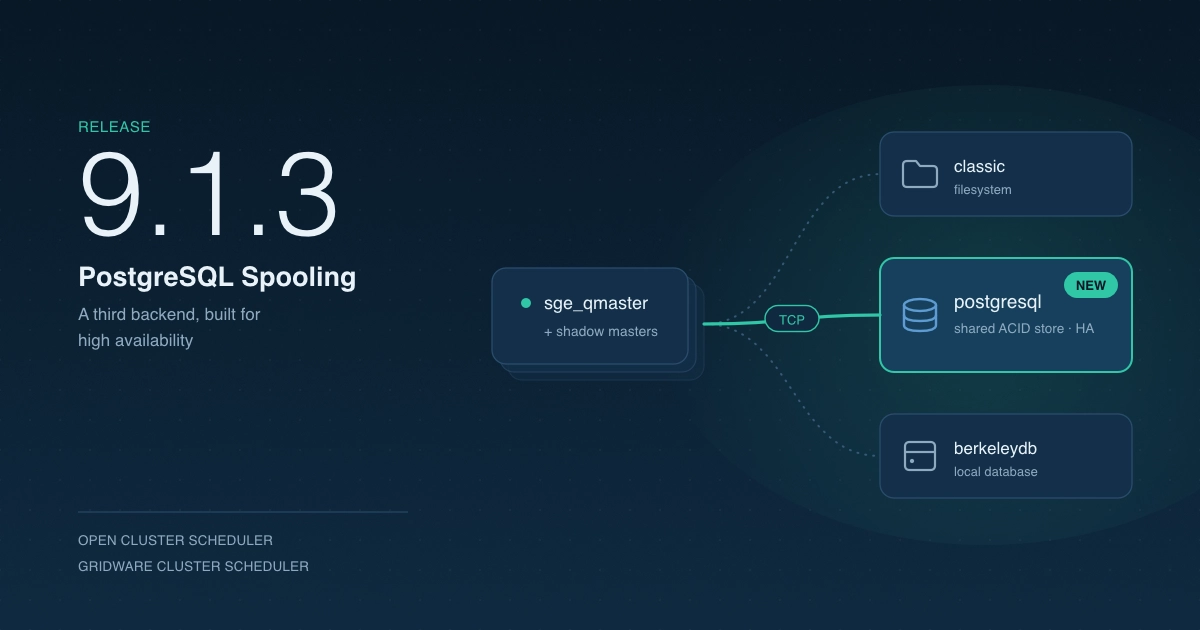
Gridware Cluster Scheduler and its opensource base, Open Cluster Scheduler (formerly Sun Grid Engine) now offer deep integration with Systemd, the modern init system for Linux. This integration opens new possibilities for system administrators to control and monitor their cluster environments with greater precision.
What is Systemd and Why It Matters
Systemd is a system and service manager for Linux operating systems that manages system processes, services, and resources. Its cgroup-based architecture provides advanced features for resource control and monitoring.
The integration between Cluster Scheduler and Systemd happens in two main areas:
- Cluster Scheduler Daemons as Systemd Services: Enhanced management of cluster core components
- Job Execution Under Systemd and Cgroup Control: Precise resource control and detailed monitoring of computation jobs. Cgroup version 1 and 2 are supported, with version 2 being the default in modern Linux distributions.
Let’s take a detailed look at both aspects and how they can optimize your cluster environment.
Cluster Scheduler Daemons as Systemd Services
Automatic Installation and Configuration
When you install Cluster Scheduler, it provides systemd service files for the master/shadow daemon and the execution daemons. These are placed in the /etc/systemd/system/ directory and automatically enabled and started during installation.
All Cluster Scheduler components run within a parent systemd slice. The slice name is requested during installation and defaults to ocs<qmaster_port>.slice. For the qmaster daemon running on port 8012, this would be ocs8012.slice.
The individual services are named accordingly as ocs8012-qmaster.service for the qmaster daemon and ocs8012-execd.service for the execution daemon.
Managing Cluster Scheduler Daemons with Systemd
To query the status of all Cluster Scheduler services on a host, you can use the following command:
$ systemctl status ocs8012.slice
● ocs8012.slice - Slice /ocs8012
Loaded: loaded
Drop-In: /etc/systemd/system.control/ocs8012.slice.d
└─50-TasksAccounting.conf
Active: active since Sun 2025-06-29 16:30:44 CEST; 13min ago
Tasks: 28
Memory: 27.1M (peak: 34.9M)
CPU: 3.178s
CGroup: /ocs8012.slice
├─ocs8012-execd.service
│ └─15491 /scratch/joga/clusters/master/bin/lx-amd64/sge_execd
└─ocs8012-qmaster.service
├─23568 /scratch/joga/clusters/master/bin/lx-amd64/sge_qmaster
└─23631 /scratch/joga/clusters/master/bin/lx-amd64/sge_shadowd
Standard systemd commands can be used for management:
systemctl stop ocs8012-qmaster.serviceto stop the qmaster servicesystemctl start ocs8012-execd.serviceto start the execution daemonsystemctl status ocs8012-qmaster.serviceto check status
Enhanced Monitoring Through Systemd Accounting
The accounting information provided by systemd offers valuable insights into Cluster Scheduler daemons’ resource usage. CPU and memory usage are enabled by default. Additionally, IO and network usage accounting can be enabled by modifying the service files
in /etc/systemd/system, e.g., /etc/systemd/system/ocs8012-qmaster.service:
IOAccounting=true
IPAccounting=true
After restarting the service, detailed usage data will be displayed:
$ systemctl status ocs8012-qmaster.service
● ocs8012-qmaster.service - Open Cluster Scheduler sge_qmaster service
Loaded: loaded (/etc/systemd/system/ocs8012-qmaster.service; enabled; preset: enabled)
Active: active (running) since Sun 2025-07-06 09:18:49 CEST; 30min ago
Docs: man:sge_qmaster(8)
Process: 736019 ExecStart=/scratch/joga/clusters/master/default/common/sgemaster start (code=exited, status=0/SUCCESS)
IP: 46.1M in, 128.6M out
IO: 2.8M read, 426.9M written
Tasks: 24 (limit: 4605)
Memory: 1.2G (peak: 1.2G)
CPU: 1min 45.750s
CGroup: /ocs8012.slice/ocs8012-qmaster.service
├─736174 /scratch/joga/clusters/master/bin/lx-amd64/sge_qmaster
└─736237 /scratch/joga/clusters/master/bin/lx-amd64/sge_shadowd
Jobs Under Systemd Control
On hosts with systemd installed, Cluster Scheduler jobs can be run under systemd control. This enables advanced features for:
- Resource control: CPU and memory limits, core binding, and device isolation
- Job management: Signaling all processes of a job, suspending and resuming jobs
- Job monitoring: Status checking and resource usage tracking
Hierarchical Organization of Cluster Scheduler Jobs in Systemd
Cluster Scheduler jobs are presented as a hierarchy of systemd units. A simple example illustrates this structure:
$ qsub $SGE_ROOT/examples/jobs/sleeper.sh
Your job 4 ("Sleeper") has been submitted
$ systemctl status ocs8012.slice
● ocs8012.slice - Slice /ocs8012
Loaded: loaded
Drop-In: /etc/systemd/system.control/ocs8012.slice.d
└─50-TasksAccounting.conf
Active: active since Sun 2025-06-29 16:30:44 CEST; 1h 27min ago
Tasks: 32
Memory: 50.9M (peak: 51.6M)
CPU: 14.171s
CGroup: /ocs8012.slice
├─ocs8012-execd.service
│ └─30003 /scratch/joga/clusters/master/bin/lx-amd64/sge_execd
├─ocs8012-jobs.slice
│ └─ocs8012.4.scope
│ ├─33430 /bin/sh /usr/local/testsuite/8012/execd/ubuntu-24-amd64-1/job_scripts/4
│ └─33433 sleep 60
└─ocs8012-shepherds.scope
└─33429 sge_shepherd-4 -bg
- The
sge_shepherdprocess runs in a separate scope (ocs8012-shepherds.scope) - The job itself runs in its own scope within the jobs slice (
ocs8012.4.scope)
sge_execd, sge_shepherd processes and the actual job processes.
For array jobs, each array task is running in its own scope:
$ qsub -t 1-3 $SGE_ROOT/examples/jobs/sleeper.sh
Your job-array 6.1-3:1 ("Sleeper") has been submitted
$ systemctl status ocs8012-jobs.slice
● ocs8012-jobs.slice - Slice /ocs8012/jobs
Loaded: loaded
Active: active since Sun 2025-06-29 16:56:21 CEST; 17h ago
Tasks: 6
Memory: 1.1M (peak: 1.9M)
CPU: 50ms
CGroup: /ocs8012.slice/ocs8012-jobs.slice
├─ocs8012.6.1.scope
│ ├─42278 /bin/sh /usr/local/testsuite/8012/execd/ubuntu-24-amd64-1/job_scripts/6
│ └─42283 sleep 60
├─ocs8012.6.2.scope
│ ├─42280 /bin/sh /usr/local/testsuite/8012/execd/ubuntu-24-amd64-1/job_scripts/6
│ └─42286 sleep 60
└─ocs8012.6.3.scope
├─42279 /bin/sh /usr/local/testsuite/8012/execd/ubuntu-24-amd64-1/job_scripts/6
└─42289 sleep 60
For tightly integrated parallel jobs a systemd slice is created for the job, containing a scope each for the master task and for the slave tasks:
$ qsub -cwd -o testmpi.log -j y -l a=lx-amd64 -pe mpich.pe 4 \
-v MPIR_HOME=~/3rd_party/mpi/mpich-4.3.0/lx-amd64 $SGE_ROOT/mpi/examples/testmpi.sh
Your job 13 ("testmpi.sh") has been submitted
# on the master host:
$ systemctl status ocs8012-jobs.slice
● ocs8012-jobs.slice - Slice /ocs8012/jobs
Loaded: loaded
Active: active since Sun 2025-06-29 16:56:21 CEST; 17h ago
Tasks: 11
Memory: 19.5M (peak: 30.0M)
CPU: 1min 6.510s
CGroup: /ocs8012.slice/ocs8012-jobs.slice
└─ocs8012-jobs-13.slice
└─ocs8012.13.master.scope
├─42518 mpirun ./testmpi
├─42519 /home/joga/3rd_party/mpi/mpich-4.3.0/lx-amd64/bin/hydra_pmi_proxy --control-port ubuntu-24-amd64-1:34879 --rmk sge --launcher sge --demux poll --pgid 0 --retries 10 ->
├─42520 /scratch/joga/clusters/master/bin/lx-amd64/qrsh -inherit -V ubuntu-22-amd64-2 "\"/home/joga/3rd_party/mpi/mpich-4.3.0/lx-amd64/bin/hydra_pmi_proxy\"" --control-port u>
├─42521 ./testmpi
└─42522 ./testmpi
# on a slave host:
$ systemctl status ocs8012-jobs.slice
● ocs8012-jobs.slice - Slice /ocs8012/jobs
Loaded: loaded
Active: active since Sun 2025-06-29 16:56:17 CEST; 17h ago
Tasks: 8
Memory: 15.4M
CPU: 14.627s
CGroup: /ocs8012.slice/ocs8012-jobs.slice
└─ocs8012-jobs-13.slice
└─ocs8012.13-1.ubuntu-22-amd64-2.scope
├─12273 /scratch/joga/clusters/master/utilbin/lx-amd64/qrsh_starter /usr/local/testsuite/8012/execd/ubuntu-22-amd64-2/active_jobs/13.1/1.ubuntu-22-amd64-2
├─12280 /home/joga/3rd_party/mpi/mpich-4.3.0/lx-amd64/bin/hydra_pmi_proxy --control-port ubuntu-24-amd64-1:34879 --rmk sge --launcher sge --demux poll --pgid 0 --retries 10 ->
├─12281 ./testmpi
└─12282 ./testmpi
Advanced Resource Management for Jobs
Job Resource Limits via Systemd
Cluster Scheduler jobs can be configured with various resource limits, either set in queue configuration or overridden at job submission. With systemd integration, certain limits are directly enforced through systemd mechanisms:
| OCS Limit | Systemd Limit |
|---|---|
| s_rss | MemoryHigh |
| h_rss | MemoryMax |
| s_vmem | MemoryHigh |
| h_vmem | MemoryMax |
Core Binding with Systemd
Core binding (processor affinity) can be requested at job submission with the `-binding` option. With systemd support, this is implemented via the `AllowedCPUs` property of the job’s systemd scope unit:
$ qsub -binding linear:2 $SGE_ROOT/examples/jobs/sleeper.sh
Your job 6 ("Sleeper") has been submitted
```
```bash
$ systemctl show ocs8012.6.scope | grep EffectiveCPUs
EffectiveCPUs=0-1
Device Isolation for Secure Job Execution
Device isolation allows restricting access to specific devices for a job – particularly important for jobs requiring exclusive access to hardware resources like GPUs. This is achieved by specifying theAllowedDevices property in the job’s systemd scope unit.
Device isolation will be automatically applied for resources defined as RSMAP when the device is configured as a
resource property (to come in the next minor release).
Until device isolation is implemented in RSMAPs, the feature can be tested by requesting jobs with a specific environment variable, SGE_DEBUG_DEVICES_ALLOW being set to a list of devices and access modes:
SGE_DEBUG_DEVICES_ALLOW="<device>=<mode>[;<device>=<mode>...]".
$ qsub -v SGE_DEBUG_DEVICES_ALLOW="/dev/nvidia0=r;/dev/nvidiactl=w" \
$SGE_ROOT/examples/jobs/sleeper.sh
Your job 8 ("Sleeper") has been submitted
`systemctl show ocs8012.<job_id>.scope | grep ^Device` will show the settings for device isolation of the job scope unit:
systemctl show ocs8012.8.scope | grep ^Device
DevicePolicy=closed
DeviceAllow=/dev/nvidiactl w
DeviceAllow=/dev/nvidia0 r
Enhanced Job Monitoring and Resource Collection
Cluster Scheduler can collect resource usage data either from systemd or through its internal PDC (Portable Data Collector) module. The data collection method can be configured via the <strong><code>execd_params USAGE_COLLECTION</strong></code> parameter:
FALSE: No online usage information is collectedPDC: Usage information is collected by the PDC module, even if systemd is availableHYBRID: Usage information is collected via both systemd and the PDC moduleTRUE: Default mode – usage information is collected via systemd if available, otherwise via the PDC module
Conclusion: Benefits of Systemd Integration for Cluster Scheduler
The integration of Cluster Scheduler with systemd provides numerous benefits for cluster administrators:
- Enhanced daemon management: Easier control and detailed monitoring of cluster services
- Precise resource control: More accurate enforcement of resource limits for jobs
- Robust job management: Improved process group management and clean termination
- Detailed monitoring: Comprehensive insights into resource usage of daemons and jobs
- Modern Linux integration: Leveraging the latest Linux features for cluster management
If you’re deploying Cluster Scheduler in your environment, systemd integration offers a powerful way to manage your cluster more efficiently and gain deeper insights into its performance.
Availability
The systemd integration is available in the daily build of Cluster Scheduler and Open Cluster Scheduler main development branch, which will be released as the next minor version (9.1.0).
It can be downloaded from the Cluster Scheduler download page
or built from the Open Cluster Scheduler GitHub repository.
Discover More
To learn more about how Gridware can revolutionize your HPC and AI workloads, contact us for a personalized consultation at jgabler@hpc-gridware.com.